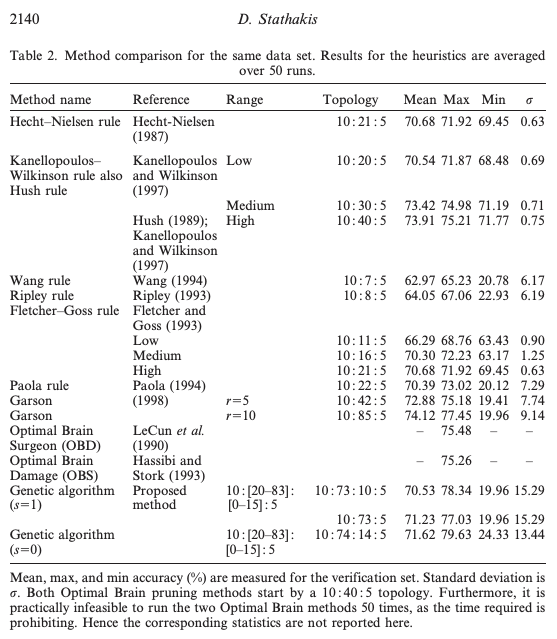
MVC is dead! Long live Flux! Er… I mean Redux!
The horror of horrors! I am that ancient in the land of software development? I have been messing around with React and realized that Model View Controller (MVC) isn’t a thing anymore. The evidence starts stacking up… People are starting to talk about moving on from MVC to “the new black”. Alas, some voice of …