How many hidden layers? How deep should your neural network be? How large or deep a fully-connected neural network can or should be?
All good questions, here we explore some answers.
This book’s chapter takes the cake for how large or deep a fully-connected neural network can or should be:
At present day, it looks like theoretically demonstrating (or disproving) the superiority of deep networks is far outside the ability of our mathematicians.
One way of thinking about fully connected networks is that each fully connected layer effects a transformation of the feature space in which the problem resides. The idea of transforming the representation of a problem to render it more malleable is a very old one in engineering and physics. It follows that deep learning methods are sometimes called “representation learning.”
Some lively discussion on stats.stackexchange.com that is more practical:

An answer quotes:
Determining the Number of Hidden Layers
| Number of Hidden Layers | Result |
|---|---|
| 0 | Only capable of representing linear separable functions or decisions |
| 1 | Can approximate any function that contains a continuous mapping from one finite space to another |
| 2 | Can represent an arbitrary decision boundary to arbitrary accuracy with rational activation functions and can approximate any smooth mapping to any accuracy |
Another answer says:
More than 2 [Number of Hidden Layers] – Additional layers can learn complex representations (sort of automatic feature engineering) for layer layers.
These nice academic folks wrote a whole paper exploring heuristics and things like genetic algorithms to find the optimal size and depth of a fully-connected neural network:
Maximum accuracy was achieved with a network with 2 hidden layers, of which the topology was found using a genetic algorithm.
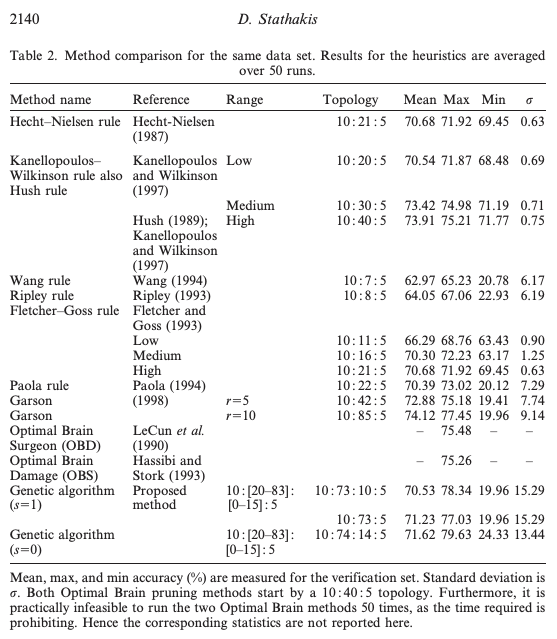
I have extracted Table 2 from the paper for your viewing pleasure:

Note that for deeper topologies (i.e. more hidden layers), the variance of accuracy and gap between max and min accuracies are far larger. This implies more time and effort is needed to figure out the best training method for a deeper network.
It seems that deeper networks can achieve higher accuracy due to better representation learning, however, they are much more unstable when training and many training iterations may be required to exceed the performance of a shallower fully-connected neural network. This implies that a should system should be in place to permutate or learn the hyper-parameter search-space.
As for how many nodes per hidden layer, the evidence seems to point towards larger numbers and taking advantage of the drop-off hyperparameter to avoid overfitting the model.